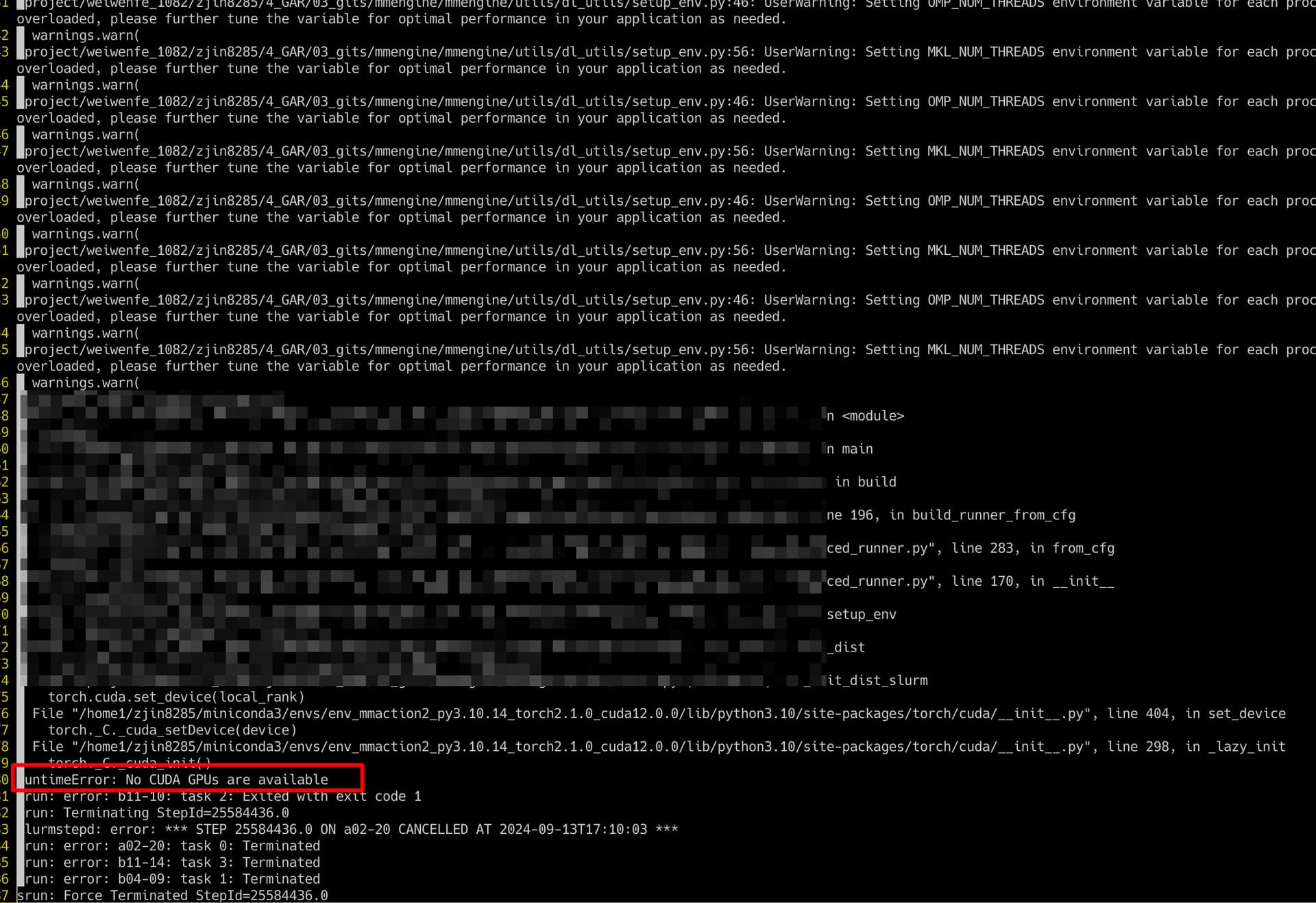
I launched a GPU job on b11-10, and the request contains 1GPU and 12CPUs for 4 nodes. However, the job immediately stoped and the log told me that RuntimeError: No CUDA GPUs are available.
The job ID is 25584436. The corresponding log is at /project/weiwenfe_1082/zjin8285/4_GAR/01_Exps/84_BB05_base_bb04_maskdecoder_depth8/train/train_slurm_25584436.log.
Here is the screenshot.
I cannot appreciate it more if you could help me solve the problem. Thanks.
I am wondering why this problem has no response after 15 days.
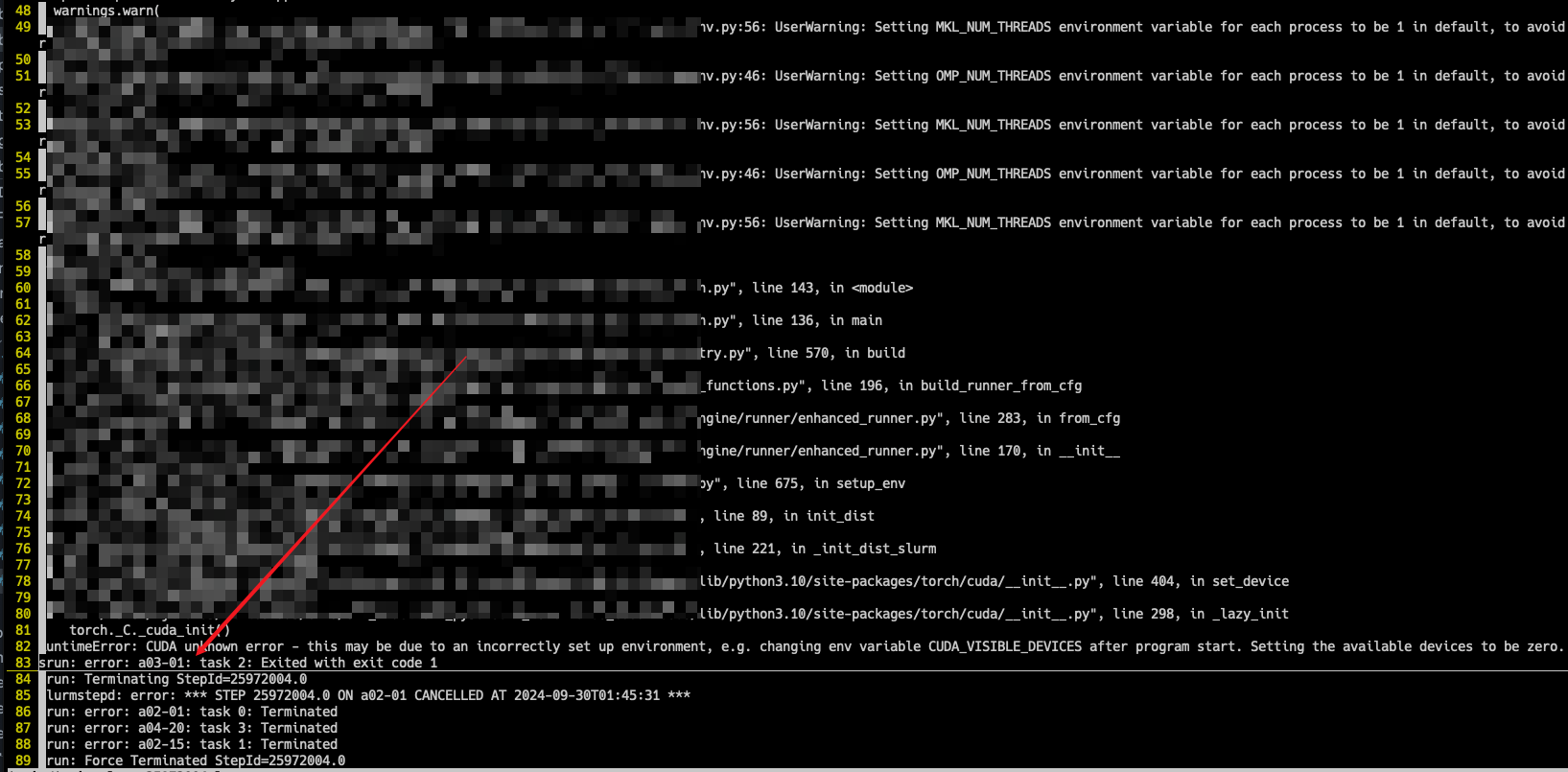
There are multiple nodes where GPUs are not available even though the job is successfully allocated. Here is another example a03-01.
Base on the link, I think it would be enough to just reboot those servers.
opened 11:18AM - 09 Dec 20 UTC
closed 08:47AM - 10 Dec 20 UTC
Help!
I install the CUDA and pytorch from official instruction, and run the
`… ``
python test_pytorch_cuda.py
```
but it returns:
```
Traceback (most recent call last):
File "test_pytorch_cuda.py", line 4, in <module>
dummy_input = torch.randn(10, 3, 224, 224, device='cuda')
File "/home/XXX/anaconda3/envs/Pt/lib/python3.6/site-packages/torch/cuda/__init__.py", line 172, in _lazy_init
torch._C._cuda_init()
RuntimeError: CUDA unknown error - this may be due to an incorrectly set up environment, e.g. changing env variable CUDA_VISIBLE_DEVICES after program start. Setting the available devices to be zero.
```
and I do set the available devices in `~/.bashrc` as followed:
```
export CUDA_VISIBLE_DEVICES = 0
```
but this do not work.
What should I do?
pytorch version: 1.7.0
CUDA version: 11.0
GPU configuration: NVIDIA A100
Same issue ‘No GPUs are available’.
system
December 20, 2024, 8:19am
4
This topic was automatically closed 60 days after the last reply. New replies are no longer allowed.