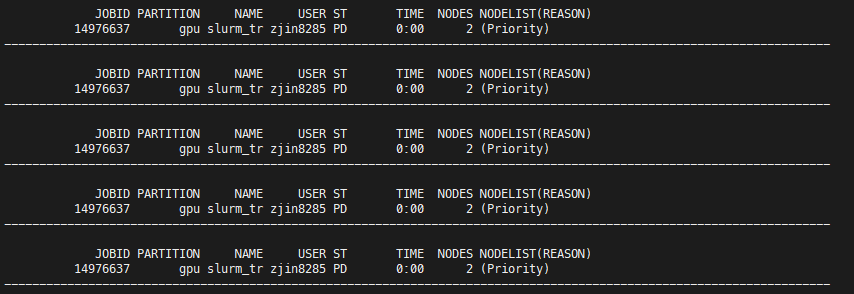
I am trying to allocate 2 A40 nodes, and each node is with 2 tasks. The job id is 14976637, and here is the command I am using.
sbatch \
--account=xxxxx \
--partition=gpu \
--gres=gpu:a40:2 \
--nodes=2 \
--ntasks-per-node=2 \
--cpus-per-task=8 \
--mem-per-cpu=2GB \
--time=12:00:00 \
xxxx.job arg1 arg2
It shows that the job is pending all the time, even with Priority.
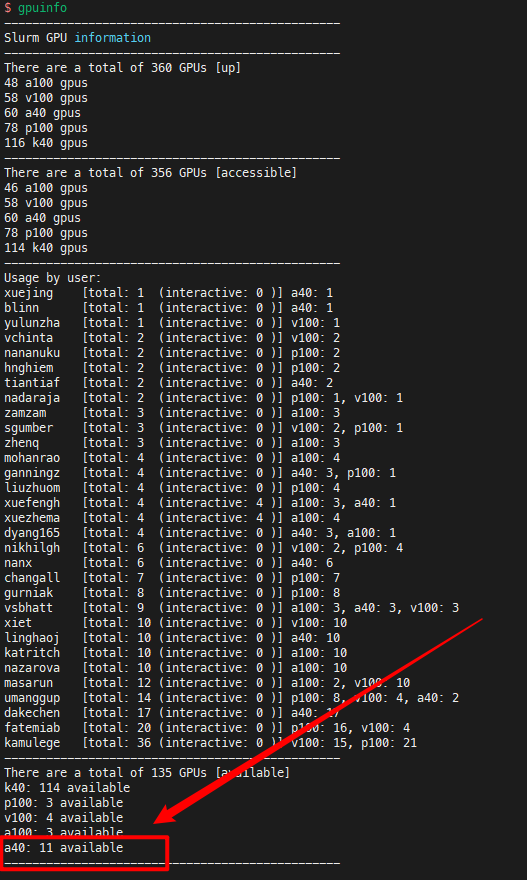
Then I check the gpu status with gpuinfo, and there are 11 A40s available.
I am wondering why I cannot allocate 4 A40 GPUs when 11 A40 GPUs are available. Thanks a lot.
After some experiments, I found one solution to the above strange problem.
In the above situation, although I cannot allocate 4 GPUs (2 nodes, 2 GPUs per node), I can still allocate 4 GPUs (4 nodes, 1 GPU per node) in most of the time.
Since my experiments do not require a huge amount of inter-node communication, so 1 GPU per node works for me.
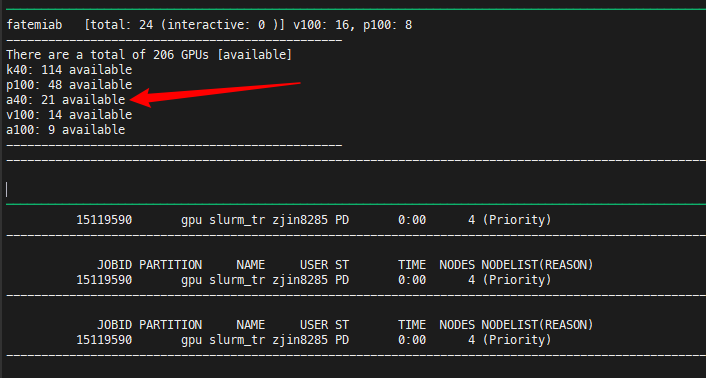
Things are getting more weird now.
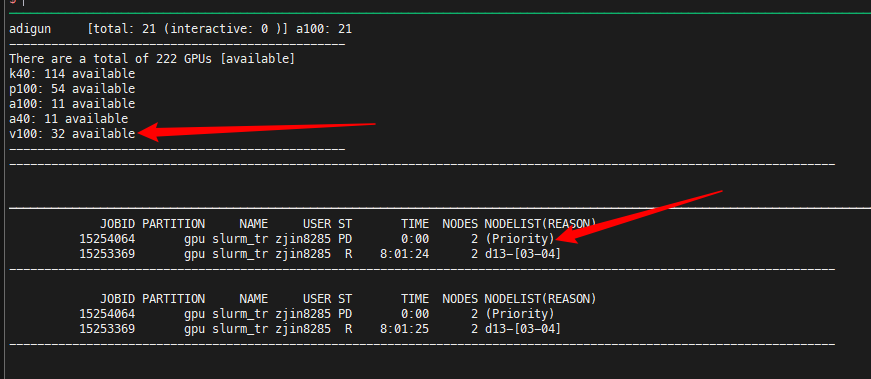
Here we have 21 A40s available, and I am asking for 4 A40s (4 nodes, 1 A40 per node). Even though I have the Priority, I still cannot get allocated.
I cannot appreciate it more if someone could solve this problem.
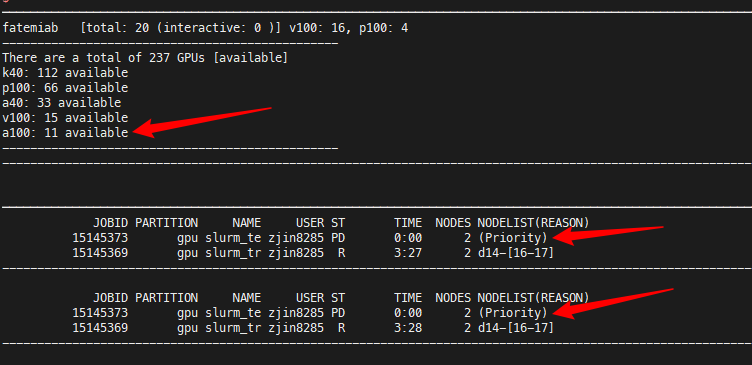
I am still facing the problem of pending for a long time when A100s are available.
I am wondering how I can get the following information for each node:
- Remaining number of CPU cores for each node
- Remaining memory for each node
- Remaining number of GPUs for each node
After I get that information, I can then adjust my request on CPU cores, memory, and GPU for my job.
I am wondering whether there are some bugs in the scheduling system.
There are 32 V100s available. And I am only trying to allocate 4 V100s. Even though I have priority tag of my job, I still have to wait for hours.
Dear Zhangyu,
Were you ever able to find the issue here? I am also trying to understand how CARC allocation works and why it takes so long for allocation even though the GPU is available. If you have any tips, please share.