When I run Matlab with Parallelization, sometimes (actually frequently) I get the following error and my program stopped. Since this issue can be addressed by simply resubmitting the job without change anything, I guess it’s not an intrinsic error in my code.
Any explanation and possible solutions?

@junjieyu Are you using parallel.cluster.Local or parallel.cluster.Slurm? It may be related to the job storage location, which is the local /tmp directory on compute nodes by default. Changing the job storage location to your scratch directory, for example, may solve it. It may also be a network latency issue, which we will have to diagnose.
Thanks for you reply. I use parallel.cluster.Slurm since I need a relative large number of CPUs, e.g.100.
I don’t know how to check where is my default /tmp file. However , I set my job storage location as my current working file (which is a folder under my scratch2 folder), see the attached image.
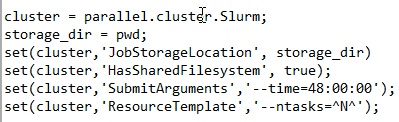 .
.
@junlieyu That JobStorageLocation is fine. This is hard to reproduce, but try adding #SBATCH --exclusive=user to your job script and similarly --exclusive=user to the SubmitArguments part of your Matlab script. Let me know if that helps.
Thanks for your reply and suggestion. I’ve tried the --exclusive=user part, however, I still get the same error.
It seems that the assigned worker can not maintain connecting for a long time. I’ve tested a very simple script that involved parallelization such as the following. It works fine.
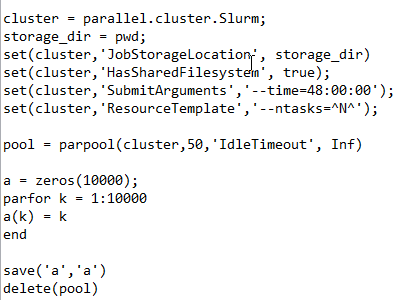 .
.
Actually, I also have this disconnecting issue previously, with the old system (not Discovery), but it occurred after around 10 hours, which at least make some progress and I can save the checkpoint and restart. However, now, on the new system, such disconnecting issue occurs after around 30 minutes, which is definitely not enough for me to collect meaningful results.
@junjieyu Does adding the IdleTimeout argument also solve the issue for your main job? Maybe you’re testing that right now. I’ll look into our configuration to see if there is something related to this that we can change.
Hi all,
I’m very late to the discussion but there was a similar question posed on the Matlab forum here: Why workers keep aborting during parallel computation on cluster? - MATLAB Answers - MATLAB Central
The relevant documentation page quoted is:
“Parallel processing constructs that work on the infrastructure enabled by parpool—parfor, parfeval spmd, distributed arrays, and message passing functions—cannot be used on a heterogeneous cluster configuration. The underlying MPI infrastructure requires that all cluster computers have matching word sizes and processor endianness.”
A homogeneous set of workers can be requested by adding to the ResourceTemplate using the --constraint option like so:
set(cluster,'ResourceTemplate', '--ntasks=^N^ --constrain=xeon-2640v4`)
This would reduce the pool of compute resources that match your request so you might play around with some of the more advanced uses of --constrain by adding a “matching or”
set(cluster,'ResourceTemplate', '--ntasks=^N^ --constrain=[xeon-2640v4|xeon-2640v3]`)
Meaning compute nodes must have one of the xeon-2640v3 or xeon-2640v4 feature but don’t mix.
If you give this a try please let us know how it goes as this issue has plagued us for some time.
Hi, @csul, sorry for replying to you late. Now I get a chance to test your very valid point. However, I have a quick question, what kind of constraint (e.g. xeon-2640v4 as you mentioned) should I specify, my lab has subscribed node, where can I check the machine’s name given a known node name (e.g. e01-38). I assume I must have some consistency when specifying constraints.
Hi, have you tried using --nodelist=e01-38? eg.
set(cluster,'ResourceTemplate', '--ntasks=^N^ --constrain=[xeon-2640v4|xeon-2640v3] --nodelist=e01-38')
Hi, @osinski, Sorry, I can not even make it work by specifying --constrain=xeon-2640v4, I was wondering xeon-2640v4 is not available, but I don’t know what should I specify.
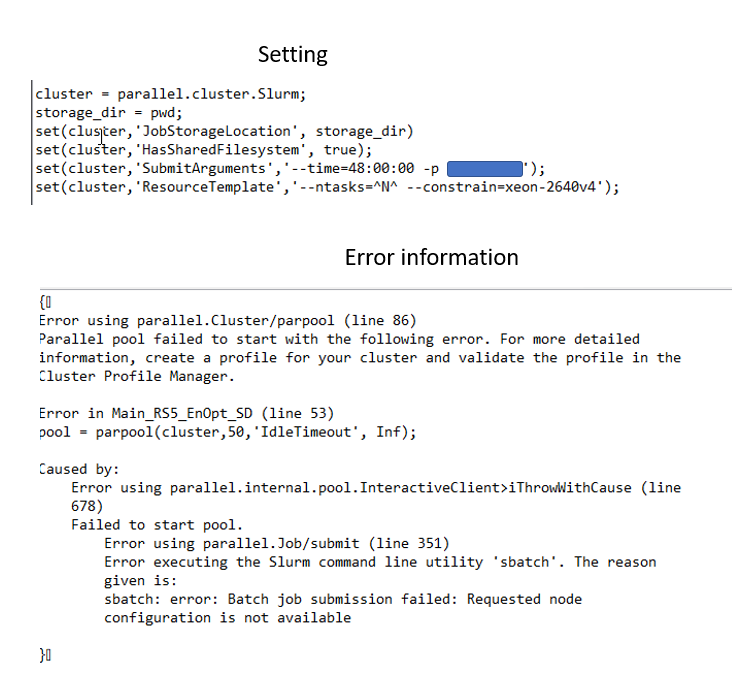
Hi @junjieyu, The error message stating that the selected node configuration is not available might be true depending on the partition. CPUs xeon-2640v4 are available only in the main partition, so if you selected a different one for your job, you might want to change that constrain to, eg. xeon-2650v2 if you selected oneweek partition. Once you login to Discovery, you can check it with the command sinfo2 and look into the last column where the CPU type is shown
1 Like
Hi, @osinski, thanks for your suggestion, changing to xeon-2650v2 works. However, I still have the loss connection issue even though after I specifying the constraint and nodelists. Also, I want to mention that I use Endeavour system instead of discovery since my lab has subscribed nodes, wondering if this makes any difference. And when I use sinfo -p to check the status for my assigned partition, there is a column called STATE and has ‘drain’,‘mix’ ,‘drng’,‘alloc’,and ‘idle’, could you explain the meaning of those for me? Thanks.
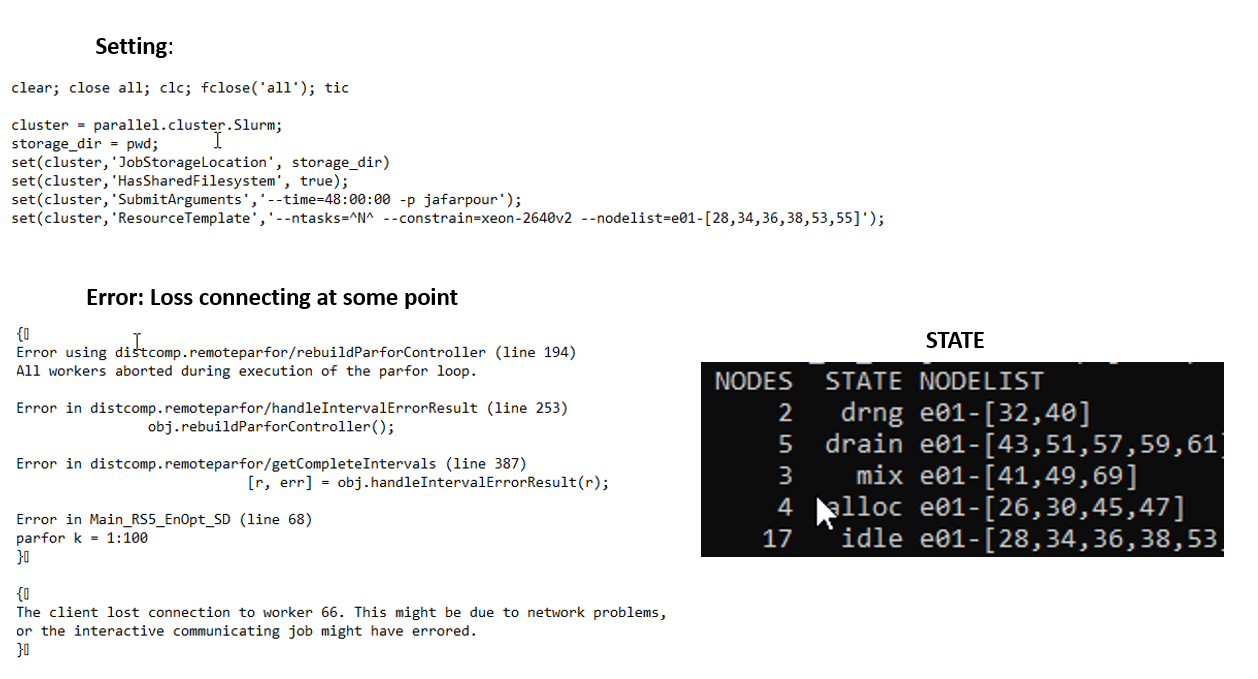
Hi,
sinfo2 is just a short wrapper around the sinfo command that shows the output in a way that tells a bit more about the nodes.
sinfo might show the following node status codes for any particular node. A (*) shown after a code means that the node is not responding.
- ALLOCATED - The node has been allocated to one or more jobs.
- ALLOCATED+ - The node is allocated to one or more active jobs plus one or more jobs are in the process of COMPLETING.
- COMPLETING - All jobs associated with this node are in the process of COMPLETING.
- DOWN - The node is unavailable for use. SLURM can automatically place nodes in this state if some failure occurs. System administrators may also explicitly place nodes in this state.
- DRAINED - The node is unavailable for use per system administrator request.
- DRAINING - The node is currently executing a job, but will not be allocated to additional jobs. The node state will be changed to state DRAINED when the last job on it completes. Nodes enter this state per system administrator request.
- FAIL - The node is expected to fail soon and is unavailable for use per system administrator request.
- FAILING - The node is currently executing a job, but is expected to fail soon and is unavailable for use per system administrator request.
- IDLE - The node is not allocated to any jobs and is available for use.
- MAINT - The node is currently in a reservation with a flag value of “maintenance”.
- UNKNOWN - The SLURM controller has just started and the node’s state has not yet been determined.
I am not a MATLAB expert, but I found that some people had similar issues to yours, and in one case the cause was a corrupted input file and in the other case the issue was with the variable initialization
corrupted file: https://github.com/idTracker/idTracker/issues/14
variable initialization: https://www.mathworks.com/matlabcentral/answers/470275-parfor-loop-with-mex-file-call-crashes-all-workers-on-one-computer-but-runs-fine-on-others
Is there a possibility that the job somehow fails on one of the worker nodes during the parfor loop?
I hope this helps to guide you to a solution.
Best regards,
Tomek
@osinski. I really appreciate all your patient help. I finally figured it out my problem is I didn’t request enough memory as my program required, that’s why I get a disconnection issue since some processor terminated because of out-of-memory. 
Now I can run without issue.
That is great to hear!