Hi there,
I’m running into an issue in the endeavour cluster in the ISI partition.
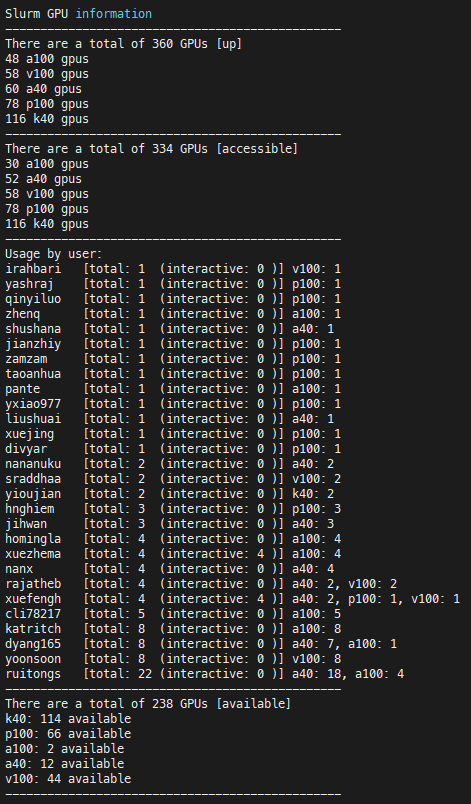
When I check sinfo -p isi, I can clearly see idle GPUs in the partition:
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
isi up 14-00:00:0 4 mix a11-[01-03],d23-01
isi up 14-00:00:0 12 idle d14-[01-02],d23-[02-06],e09-[13-17]
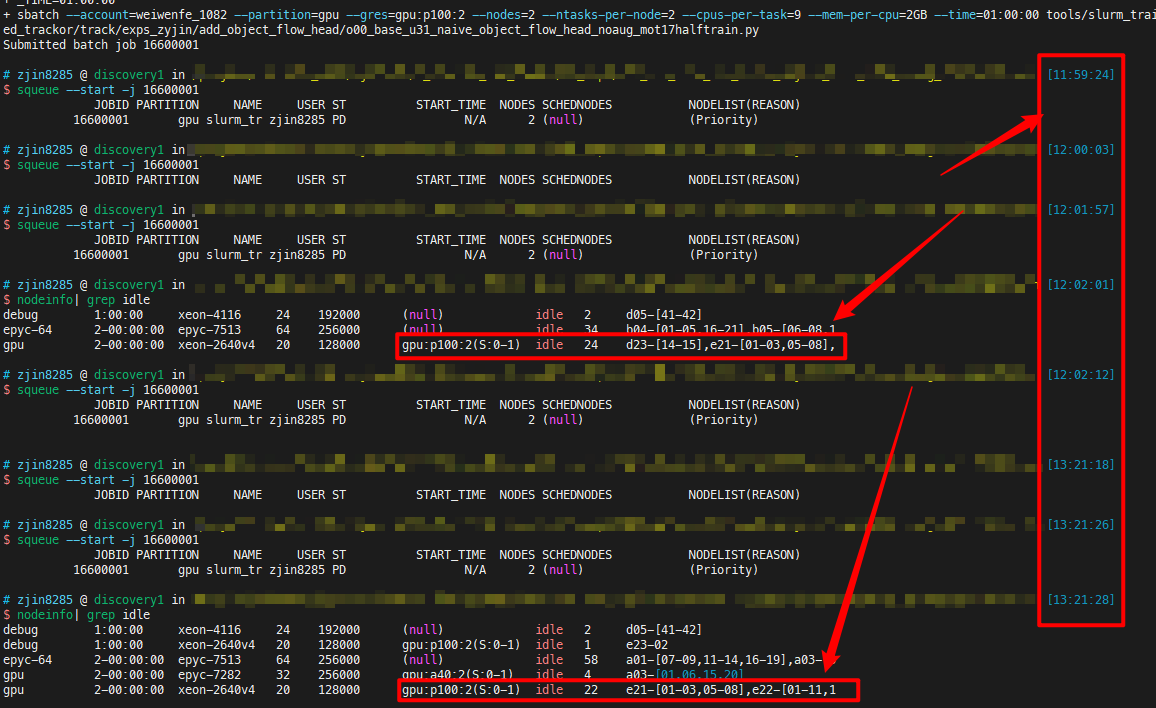
But when I try to explicitly request one of the idle GPUs, I get stuck at pending for a long time:
[jh_445@endeavour1 ~]$ salloc --partition=isi --gres=gpu:k80:1 --time=4:00:00 --ntasks=1 --cpus-per-task=2 --mem=32GB
salloc: Pending job allocation 8865988
salloc: job 8865988 queued and waiting for resources
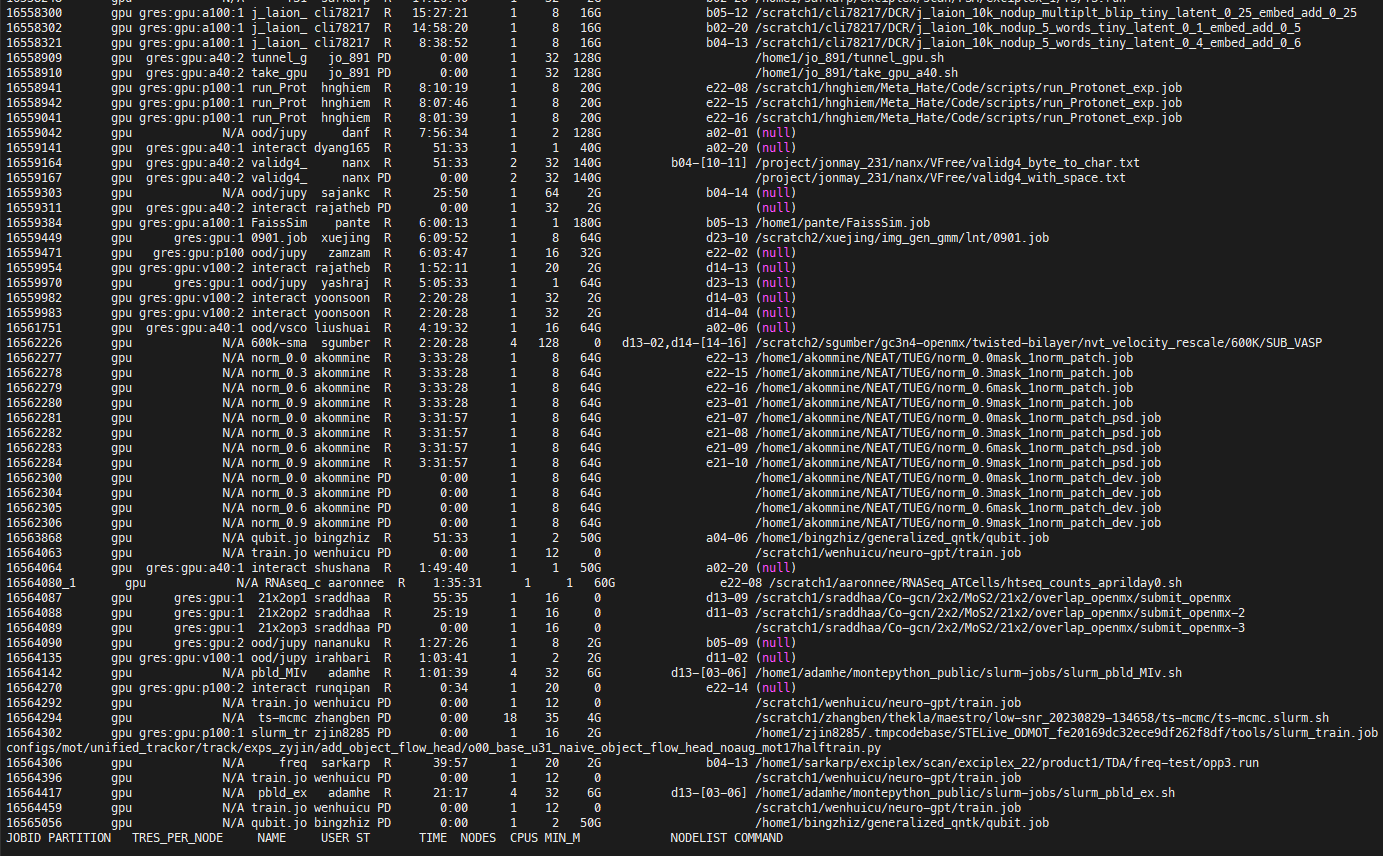
Trying out squeue -p isi --start -u jh_445 also doesn’t provide a good sense of when the GPU becomes available:
JOBID USER ACCOUNT PARTITION QOS NAME ST TIME TIME_LIMIT NODES CPU S:C:T NODELIST(REASON)
8795625 jh_445 jonmay_23 isi normal xfmr-zh-en-4gpu-1-1-shuf PD 0:00 5-00:00:00 1 1 *:*:* (Resources)
8795626 jh_445 jonmay_23 isi normal xfmr-zh-en-4gpu-0-1-shuf PD 0:00 5-00:00:00 1 1 *:*:* (Priority)
8865988 jh_445 jonmay_23 isi normal interactive PD 0:00 4:00:00 1 2 *:*:* (Priority)
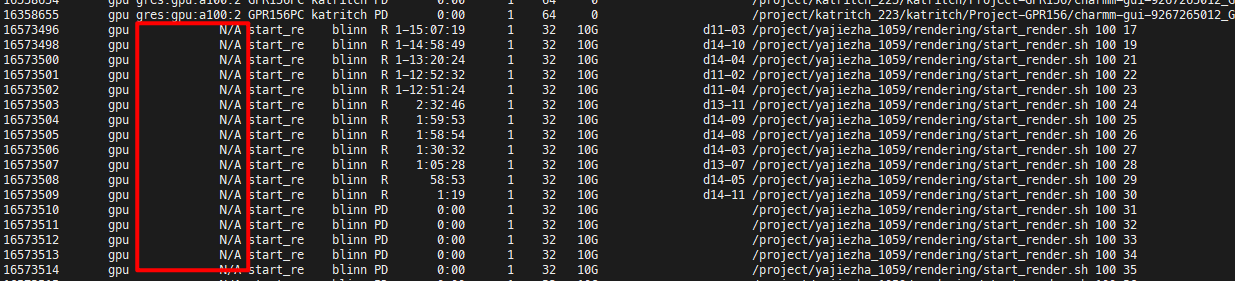
I know there has been a lot of related posts on this issue (e.g. here and here), and I really don’t think it’s because of the inherent nature of the fairshare algorithm (unless this algorithm withholds GPUs from lower-priority users, even if no one else is using them?). I can’t see anyone else in the partition requesting or using the idle GPUs, and I get stuck in the pending state even after loosening the restriction and asking for any generic node. This has been a recurring problem with several people I know, and I’ve never encountered this issue before in previous high-powered computing clusters. I would really appreciate if you guys would mind taking a closer look.
Thanks!
cc @jonmay